Human-alphabet parsing in the wild. Internet-video frames show people forming the letters of our model name, Spectrum, while the model segments diverse clothing and body parts, handling unseen items such as sarees, across complex poses and styles.
Existing methods for human parsing into body parts and clothing often use fixed mask categories with broad labels that obscure fine-grained clothing types. Recent open-vocabulary segmentation approaches leverage pretrained text-to-image (T2I) diffusion model features for strong zero-shot transfer, but typically group entire humans into a single person category, failing to distinguish diverse clothing or detailed body parts. To address this, we propose Spectrum, a unified network for part-level pixel parsing (body parts and clothing) and instance-level grouping. While diffusion-based open-vocabulary models generalize well across tasks, their internal representations are not specialized for detailed human parsing. We observe that, unlike diffusion models with broad representations, image-driven 3D texture generators maintain faithful correspondence to input images, enabling stronger representations for parsing diverse clothing and body parts. Spectrum introduces a novel repurposing of an Image-to-Texture (I2Tx) diffusion model—obtained by fine-tuning a T2I model on 3D human texture maps—for improved alignment with body parts and clothing. From an input image, we extract human-part internal features via the I2Tx diffusion model and generate semantically valid masks aligned to diverse clothing categories through prompt-guided grounding. Once trained, Spectrum produces semantic segmentation maps for every visible body part and clothing category, ignoring standalone garments or irrelevant objects, for any number of humans in the scene. We conduct extensive cross-dataset experiments—separately assessing body parts, clothing parts, unseen clothing categories, and full-body masks—and demonstrate that Spectrum consistently outperforms baseline methods in prompt-based segmentation.
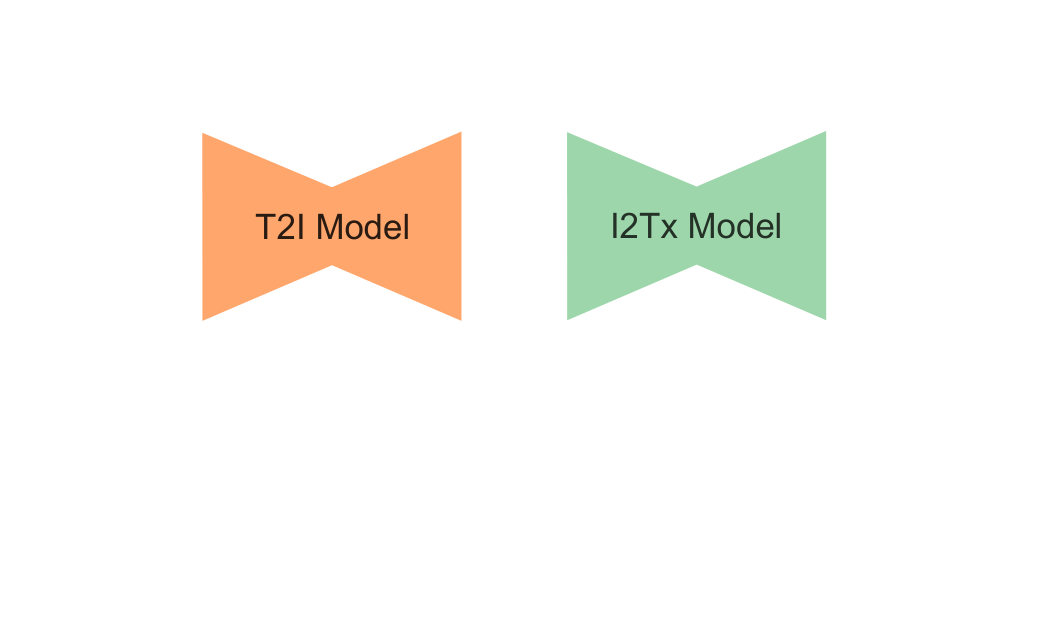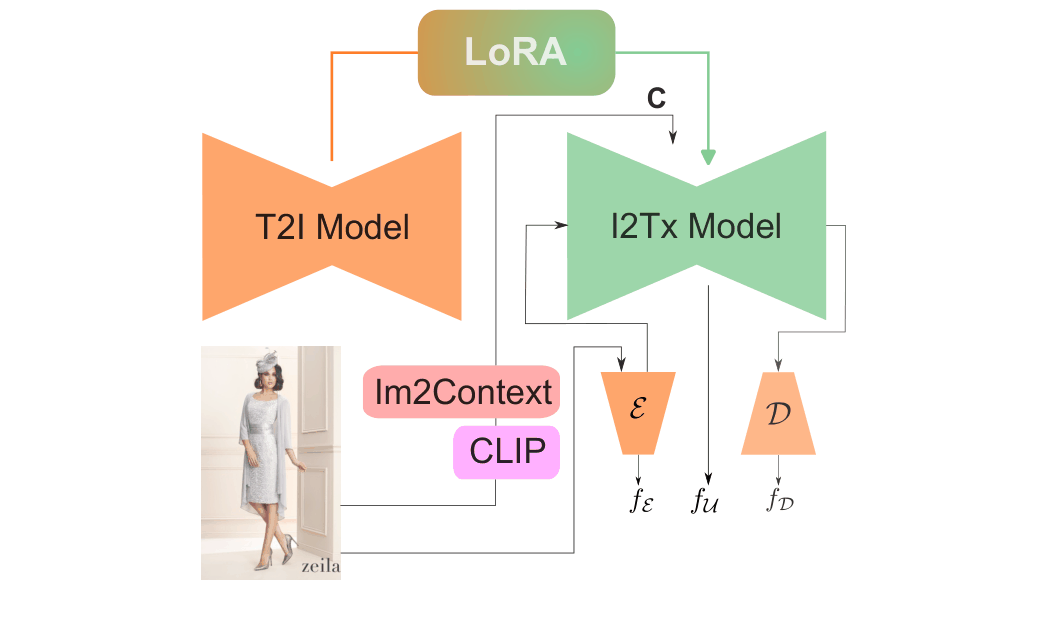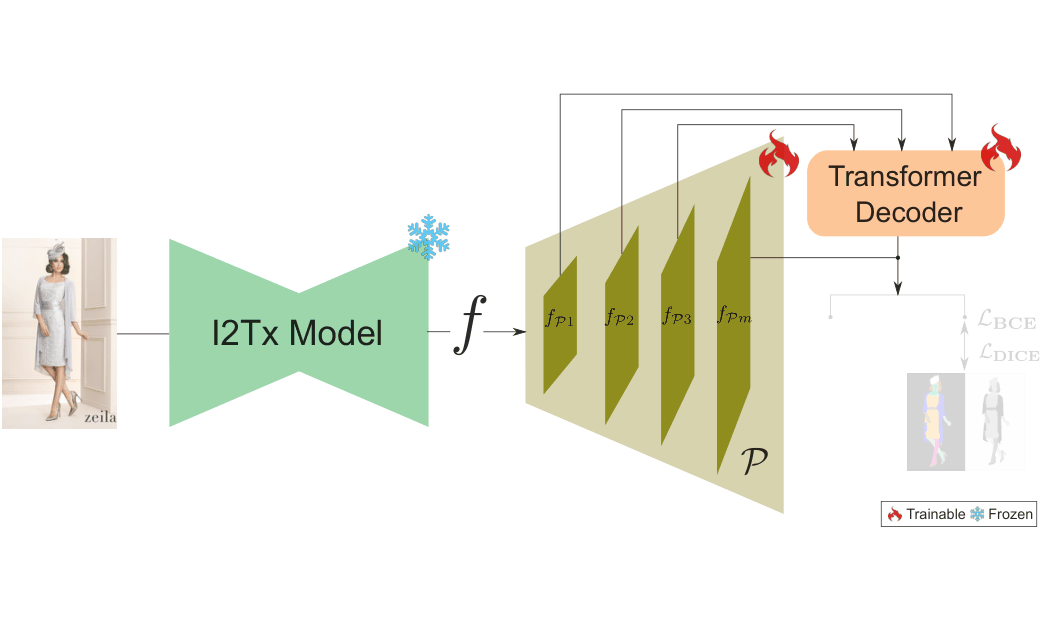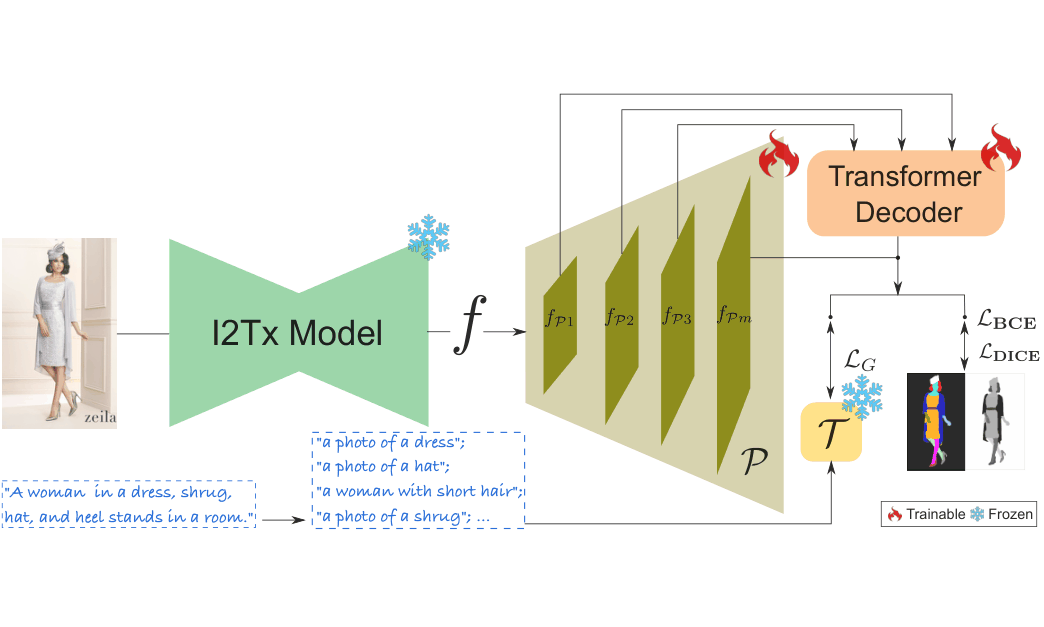
Base Stable Diffusion weights are merged with 3D-texture LoRA matrices, and a context embedding C from IM2CONTEXT and CLIP-VISION drives a single forward pass in the I2Tx model. Concatenating encoder, denoiser, and decoder representations yields the texture-aligned feature f for clothing and body-part parsing. Frozen I2Tx features from image x feed the pixel decoder 𝒫 and transformer, producing N class-agnostic masks m optimized with ℒBCE and ℒDICE. Key prompt phrases, embedded by frozen 𝒯, are contrastively aligned to m via ℒG.
Hover over images to see the results ↖
Tap and hold images to see the results ↖
Hover over images to see the results ↖
Tap and hold images to see the results ↖
We thank Michael J. Black for valuable feedback. We also thank Peter Kulits, Zitian Zhang, Zhening Huang, and Samuel Sartor for proofreading and insightful discussions. This work was conducted during an internship at Adobe Research.
